Training of translation models
Best translation quality for companies
All sources as a training basis: websites, glossaries, databases, documents, TMS exports
Extraction of training data automatically and independently
Validation, cleansing and processing of language data
Training and fine-tuning of language models
Evaluation of translation results in your own environment

Training of translation models
In a nutshell
Your previous translations are a treasure trove of data that you should use to your advantage.
Through past investments in translation and proofreading, your company has created a large amount of language data that is of very good quality.
We can make this data usable for you and thus achieve the quality of human translation – with the efficiency of machine translation.
Gain speed in global rollouts of content and campaigns and make the work of your local subsidiaries easier.
What steps does the training go through?
Training machine translation in your corporate language consists of 5 steps:
1. Collection – Collect language data from websites, glossaries, language databases, documents, TMS exports
2. Extraction – Extracting the language pairs from the collected data
3. Processing – Validating, cleaning and processing the language data for the trainings
4. AI-Training– Training the language models on the translation knowledge
5. Evaluation – Evaluation of the language models by the customer in the model blind test
How do you train translation models?
Translate learns corporate language like a translator.
1. Collection:
You would explain language rules to a new translator. You might show them a directory of product names. There may be a glossary in which you have defined technical terms and translations. In some cases, you can even include a document on corporate language and tone-of-voice. Or you don’t have a structure and instruct the translator to look at your publications and keep that style. We do this part of the collection fully automatically as soon as we receive the information.
2. Extraction:
From all the sources and data that are made available to us, we have to find pairs of sentences.
Sentence pairs are the currency of translation model training.
For example, an example of a training set at KWS Saat is:
Deutsch: “Und so widerstandsfähig wie Roggen ist kaum ein anderes Getreide.”
Englisch: “And there is hardly any other cereal that is so resistant as rye.”
This sentence contains both grammar and the linguistic tonality that KWS speaks of “cereal” while generic translation models would translate “grain”.
3. Processing:
The data we receive is usually unsorted. Especially in published documents and websites, we find texts that have not been translated 1:1 in the same place and appropriately. That’s why we have developed our own technology to find and process these pairs of sentences.
This makes training economically and time-wise.
4. AI Training:
We bring together the processed language data in a training corpus. Of course, with a control group and optimally prepared for the model to be trained. The training cycles are then run through until the results are good enough for evaluation.
5. Rating:
In the evaluation phase, we make the results available in a separate area. There, the translation managers can validate and check the results of the trained business models with those of generic models or previous translations.
And how does AI continue to learn?
Translate learns with every proofreading and publication.
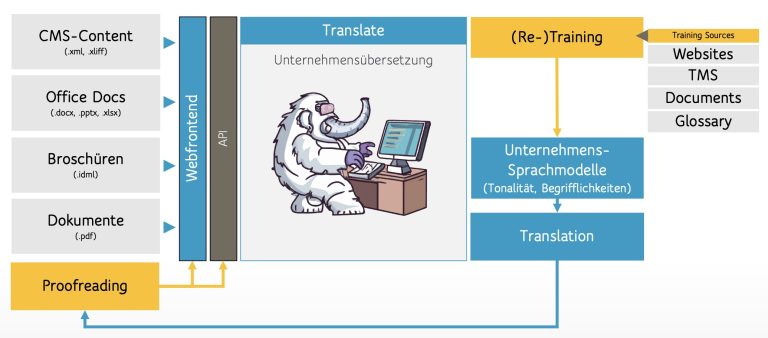
During operation, we provide you with your trained translation models via API and web frontend. With each translation, you can add changes from the proofreading. In addition, we periodically use the training sources and check which changes have taken place in the vocabulary in order to train them back into the model.
And if we have ad-hoc changes and, for example, release a new product? In our training center, you can manage the changes directly and determine that translations have to be changed immediately. We also regularly include your adjustments in the training center in the model training.
Why train translation models?
Summary:
Learning the special terms, tonality and specific naming coventions of the company – for the highest translation quality.
Continuous learning and improvement in operation – for future best results.Processing of all data sources for the training – whether websites, TMS, glossaries, documents or other sources – for the use of all language data that has been generated so far.
How much does it cost:
We offer the complete process from the collection to the provision of the evaluation environment and the evaluation of the training results – at a flat rate of €5,000 per language.How long does it take to train an AI?
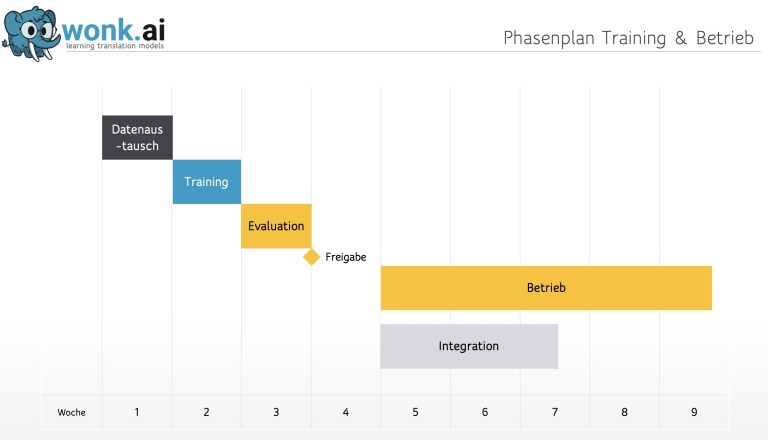
Teaching your corporate language to Translate is possible very quickly.
We were able to complete the data exchange, training and evaluation phases in just a few working days. A common value is about 3-4 weeks. The critical path here is access to the data – especially in the case of third-party systems such as translation memory systems. And the availability of those responsible for translation for evaluation.
In der Evaluation werden etwa 200 Satzpaare geprüft, Sie sollten mit etwa 16 Stunden Aufwand rechnen.
What can Translate do?
Translate combines the economics of machine translation with the quality of human translation.
Website Projects and Content – . XLIFF
.xml, .xlif and other formats that a CMS can export, Translate avoids and translates the language true to format.
Downloads – .PDF
Translate translates already set documents in .pdf format into the desired languages.
Office documents – Word, Excel, PowerPoint
Classic documents that arise in daily office work can be translated with Translate. And keep your formatting and design.
Own corporate language
Within a training project, we train Translate based on existing content from websites, translation memory systems (TMS), documents of any form and existing glossaries.
Catalogs, brochures and printed matter – .IDML
This content is usually created in Indesign in .idml format. Translate translates the content so that it remains editable and in Indesign format.
100% DSVGO compliant
Integrated through API into Microsoft Azure. Data in EU & Germany – or on-premise if desired




The training for translate is clear…